AI / Local Compute
Experimenting with LLMs
Using the llama-cpp inference runtime with smaller GGUF transformer models on old dusty hardware.


Hardware
The goal was to run a local LLM on whatever was already sitting around — no GPU, no cloud, no new hardware.
| Machine | Lenovo Desktop |
| CPU | Intel Core i3-6100T @ 3.20GHz |
| RAM | 3.8 GB |
| OS | Debian 12 |
Install llama.cpp
llama.cpp is a C++ inference runtime for transformer models in GGUF format. It runs on CPU with no GPU dependencies, making it the right fit for constrained hardware.
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp
Build without GPU support:
mkdir build cd build cmake .. -DLLAMA_CUBLAS=OFF
Model Selection
With under 4 GB of RAM, model selection matters. The smallest viable chat model
is tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf — a 1.1B parameter model
quantized to 4-bit, which fits within the memory budget with room to spare.
For reference, this is a 1.1B parameter model. ChatGPT is estimated to have approximately 1.7 trillion parameters — roughly 1,500× larger.
Running the Interface
./build/bin/llama-cli \ -m models/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf \ -c 1024 \ -n 256 \ -t 2
Prompt & Output
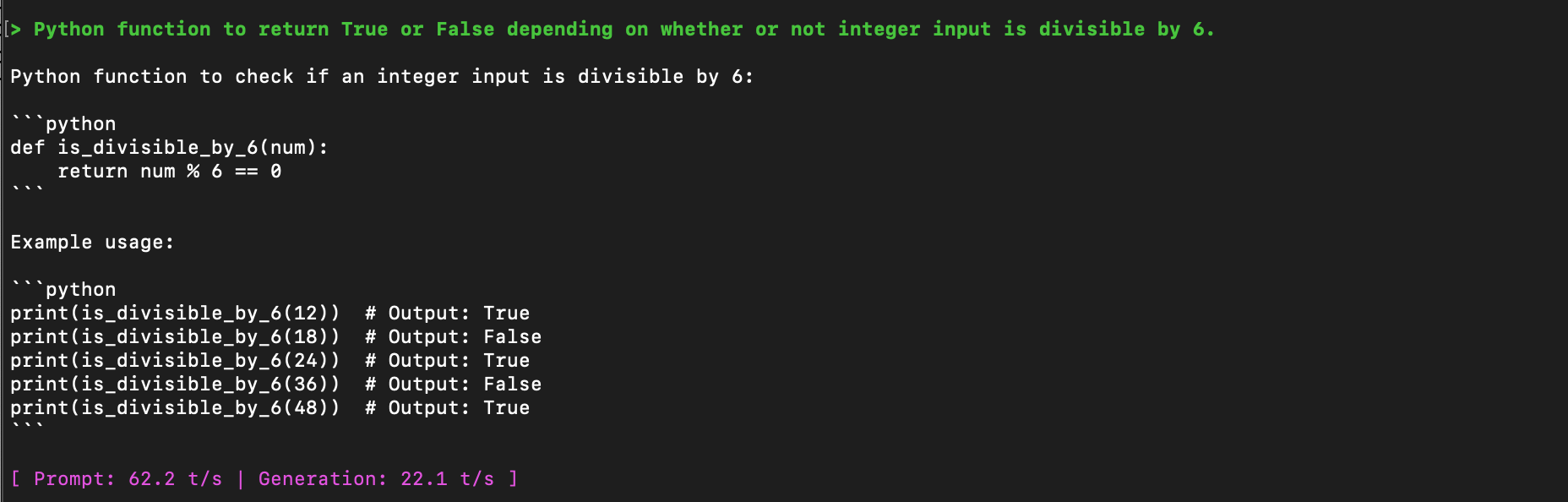
The model runs and responds. Output is coherent but the examples it generates are incorrect — expected at this scale. At 1.1B parameters the model has general language structure but limited factual reliability.
What This Demonstrates
- CPU-only LLM inference on a 10-year-old desktop with under 4 GB RAM
- GGUF quantization (Q4_K_M) as the key to fitting a model in constrained memory
- llama.cpp as a no-GPU, no-cloud inference runtime for local experimentation
- The scale gap between a local 1.1B model and production LLMs like ChatGPT (~1.7T)
Further reading: Interesting reads on AI